










Ultra-long read 3rd-generation DNA sequencing
The complete genomes of two economically relevant plant species; tomato and potato were sequenced using

TKI-U Discovery toolkit for small-RNAs relevant to plant breeding
This project aimed to guide plant breeding researchers onto the path of small RNA discovery/analysis

RepeatDB
Repeat regions are important sequences within a chrosomome. They play roles in regulation, genome structure,
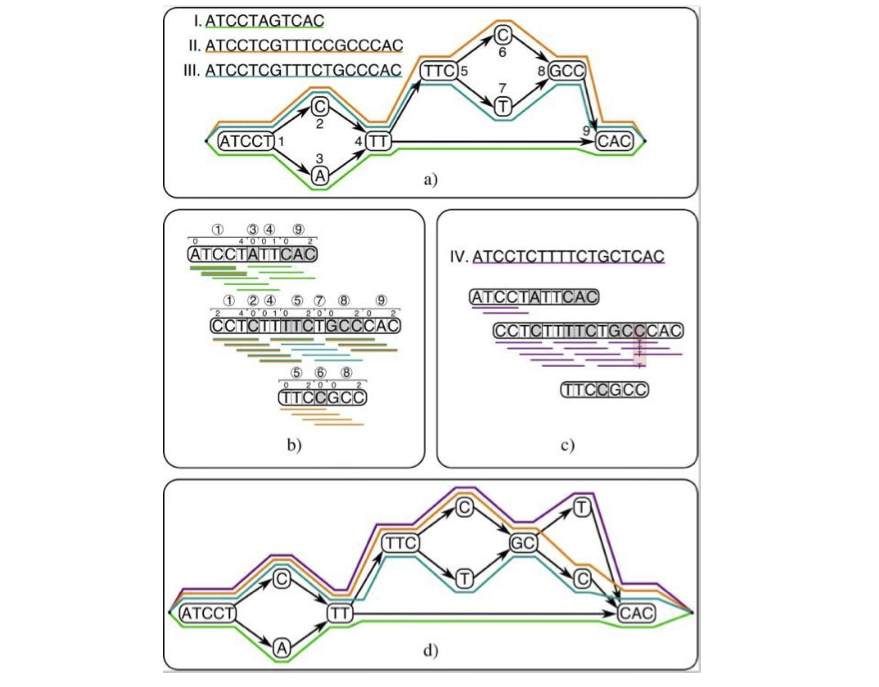
Pangenome read alignment and variant calling
Pan-genome references, also known as graph reference genomes, can represent multiple strains in a single
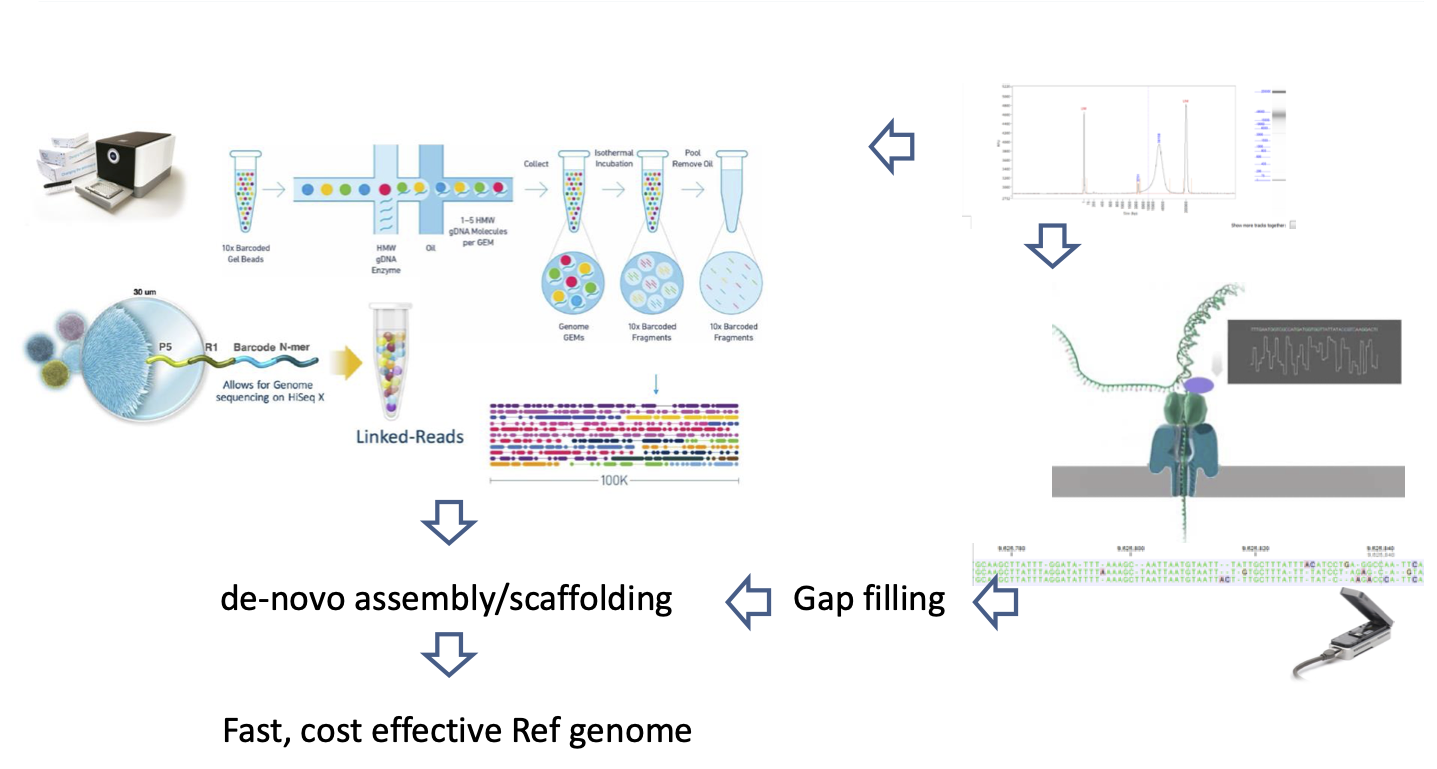
Improving genome assemblies by combined 10XGenomics and nanopore technology
This project’s aim was to generate an improved reference genome of potato (Solanum tuberosum Phureja
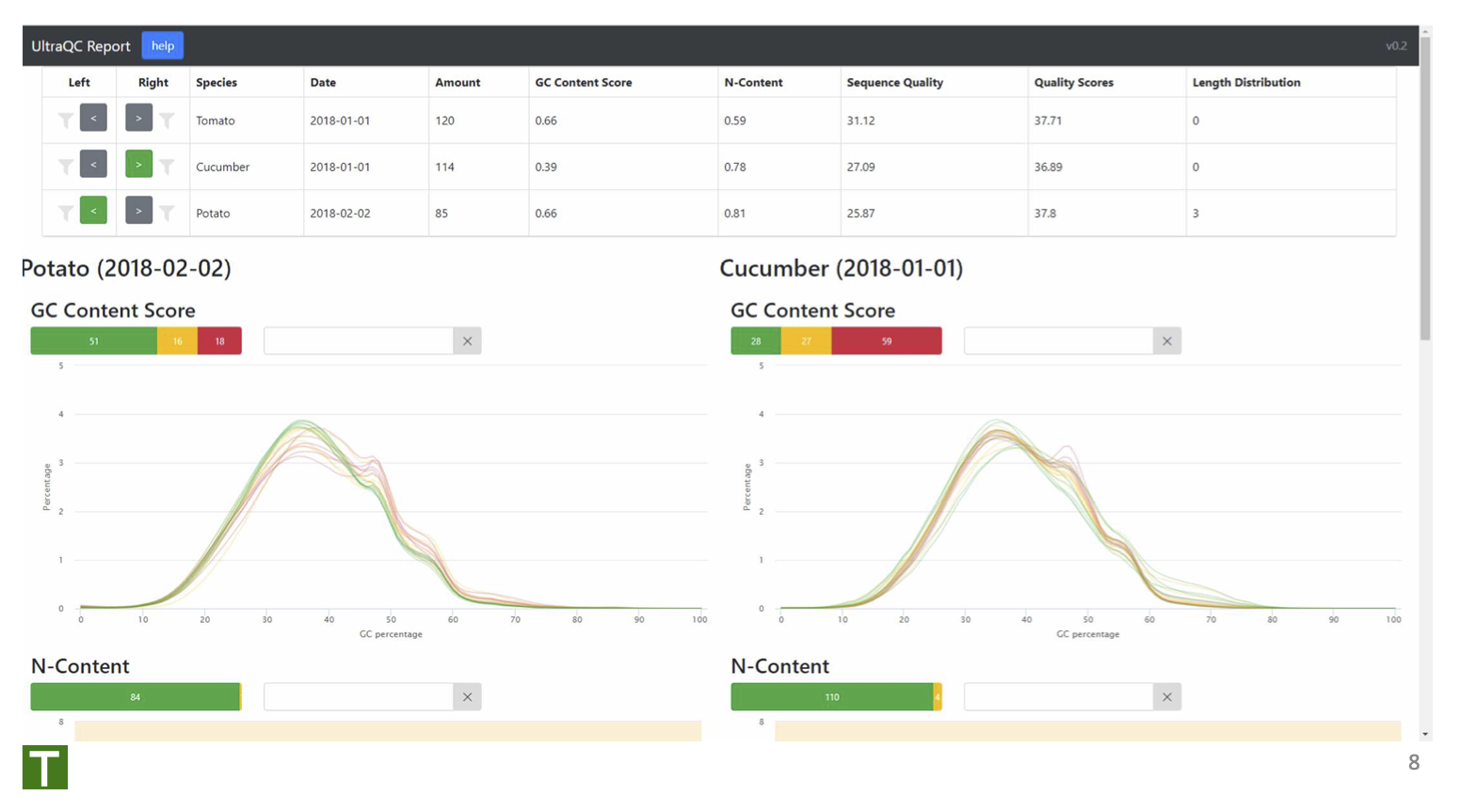
High-throughput quality assessment of sequencing data (student project)
The aim of this project was to provide key summary statistics from whole genome DNA

Haplotype reconstruction algorithms
Long-read sequencing enables for the first time to reconstruct chromosome length haplotypes. We have recently

Exploring pan-genomics for crops
The aim was to evaluate how pan-genomics can facilitate data management and ease specific data
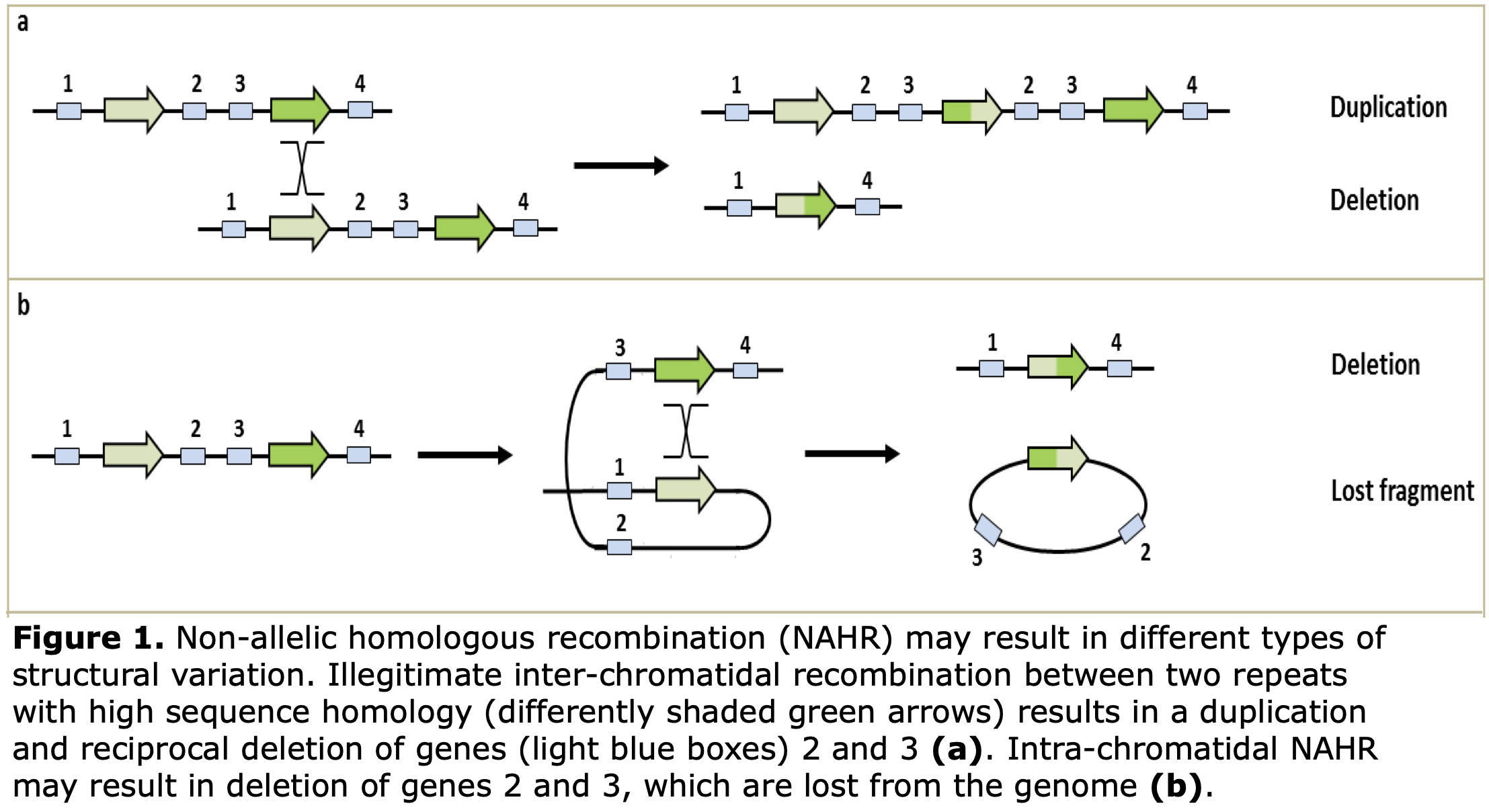
Copy Number Variation
The key challenge is to reliably detect CNV on (very) low coverage datasets, to link
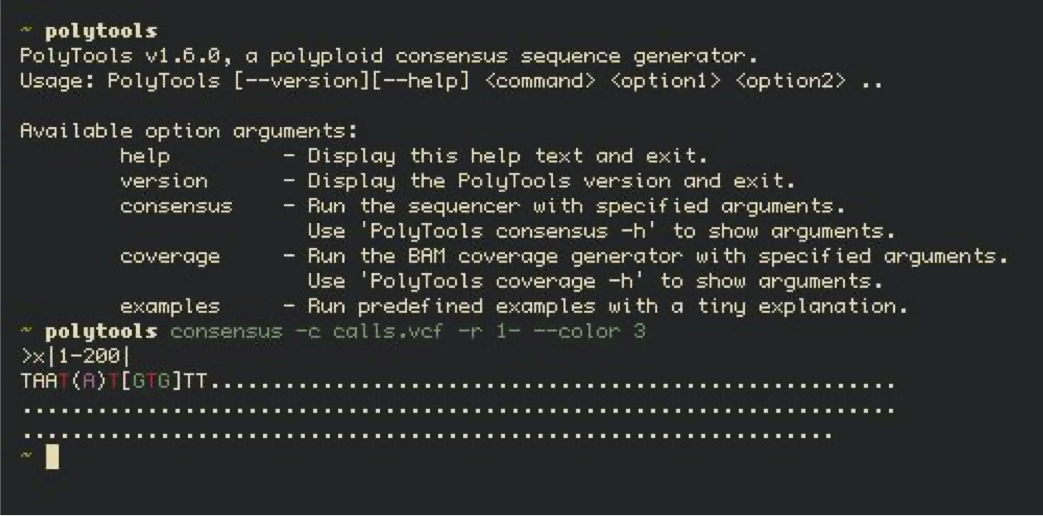
Consensus sequence generator (student project)
The objective of the consensus sequence generator was to develop a command-line tool that allows
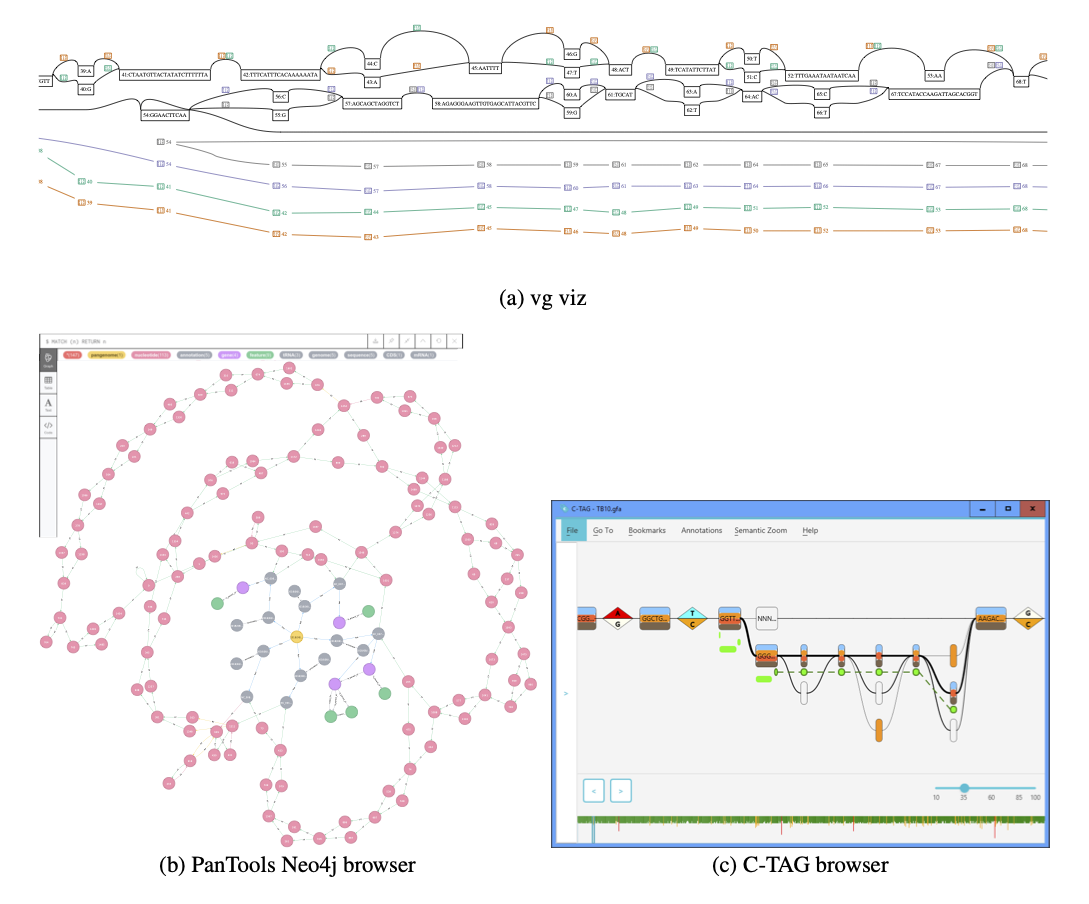
Comparison of pan-genome approaches (student project)
What are the functionalities, limitations, strengths and weaknesses of various pan-genome representations?The aim was to
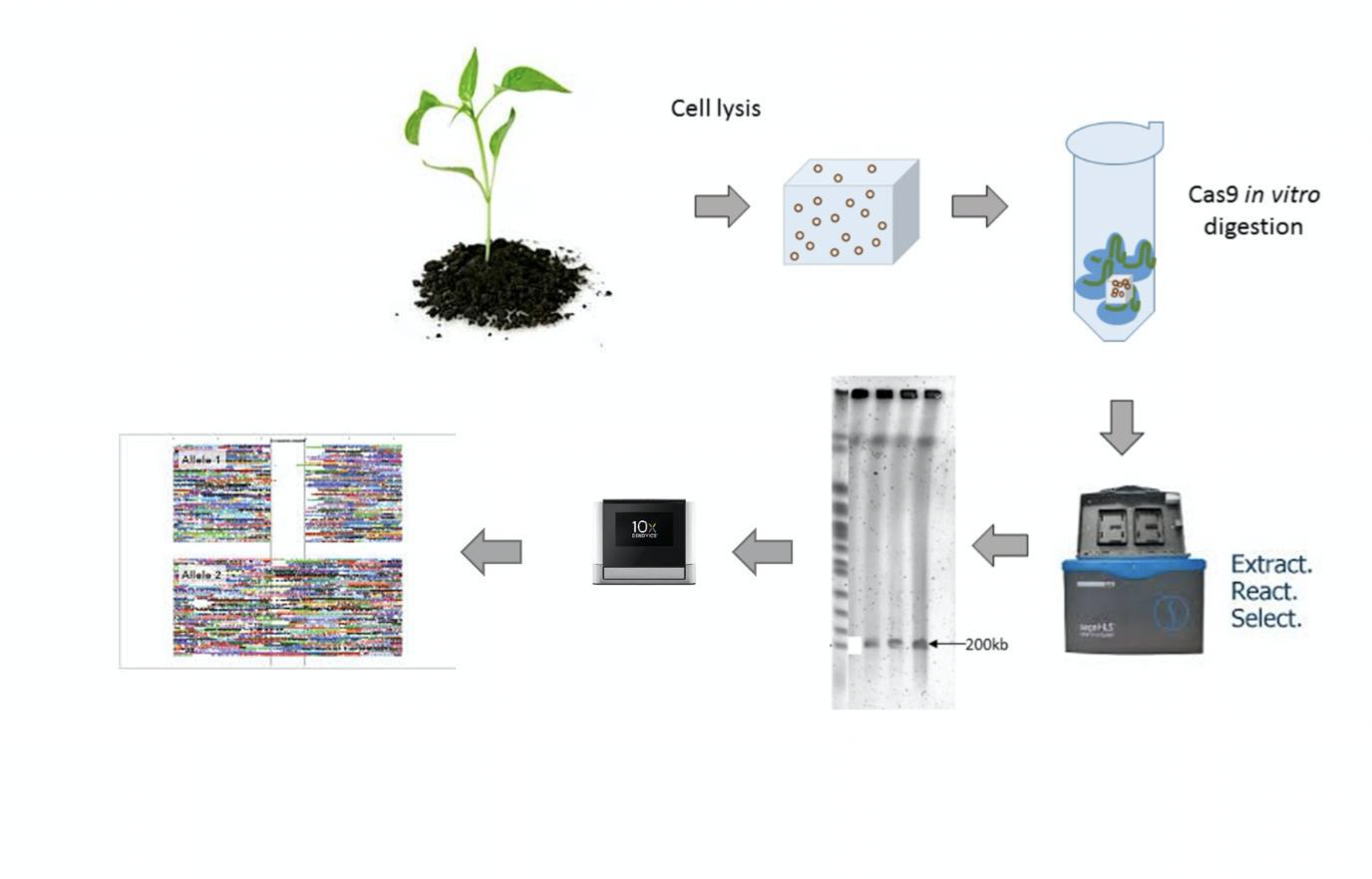
Building the Green Hapmap, 10X Genomics
A promising technology to deal with haplotype assembly in a cost-effective manner is 10x Genomics.
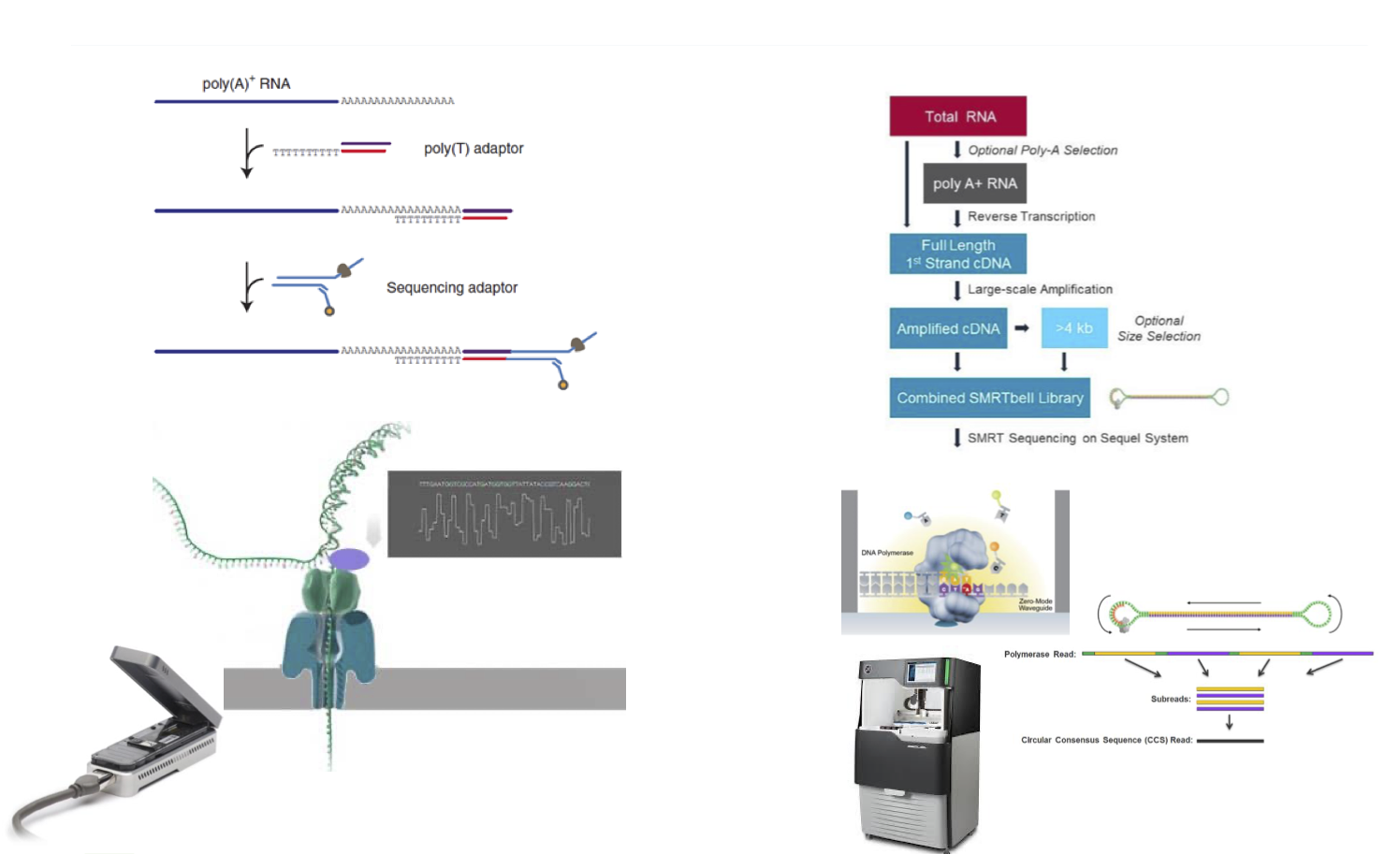
Benchmarking Crop Direct RNA sequencing versus full length IsoSeq
The aim was to explore technological possibilities for direct RNA sequencing using nanopore technology compared

Application of candidate gene prioritization to QTL data
In this project we used gene function prediction and functional overrepresentation in QTL regions to